
Introduction
In this blog post, I will walk you through how to build a fast and simple image search tool. Traditional image search engines require extensive engineering efforts to develop and are difficult to adapt to my own albums. In this project, my partner, Ran Li, and I developed an image search application that uses multimodal foundation models to search for highly accurate and relevant results. By following this blog post and our code base, you can easily build one yourself.
This project was a side project that we did to explore large foundation models. Our code is publicly available at https://github.com/Ivan-Zhou/image-search.

Motivation
Traditional image search engines use complex algorithms to match a user's keywords with images in their database. These algorithms rely on explicit features, such as image descriptions, colors, patterns, shapes, and other image characteristics, as well as associated texts or webpage contents. Developing these algorithms requires extensive engineering effort over time, and they are difficult to adapt to new, private photo stocks.
In contrast, foundation models are very generalizable and capable, as you have seen in ChatGPT and GPT-4. The multimodal foundation models we explored in this project, CLIP (Contrastive Language-Image Pre-Training) and GLIP (Grounded Language-Image Pre-Training), are great at capturing both abstract concepts and fine-grained details. They perform more sophisticated comparisons with a large vocabulary to retrieve relevant images. These capabilities make them excellent candidates for the image retrieval task.
Step-by-Step Walk Through
Here is an overview of our system design. Don't feel overwhelmed by the details. We will walk you through each component and show you how they work through code and examples.

Overview of the image search app’s system design
Data
You can try searching with your own photos. That will be more fun! If you don’t have images to try on. I prepared a subset of ImageNet with 10,000 samples. You can download them here. Below I show some example images from the dataset.

Compute Image-Text Similarity with CLIP
We will begin with the simplest version of computing image-text similarity using the CLIP model. CLIP is a foundation model trained on multimodal input. It encodes both images and text into the same vector space, allowing us to compare their similarity score by taking the inner product of each image-text vector pair.
Note that there are implementations of CLIP from both OpenAI and HuggingFace. Through benchmarking, we found that OpenAI's implementation is 14x faster than HuggingFace's. Therefore, we chose OpenAI's CLIP library.
| Implementation | Latency (sec / 1000 images) |
|---|---|
| OpenAI CLIP | 9.17 |
| HuggingFace CLIP | 128.91 |
Below is the code to read images and compute pair-wise similarity between the target query and each image.

The inputs are:
A list of N strings representing the paths to read all images.
A string representing the search query.
The output is a vector of size N that represents the pair-wise similarity score between the target query and each image.
Using the output similarity scores, we can sort images in descending order based on the scores to identify the most relevant images for the search query.
For instance, the following are the top three images we found using the search query a roasted chicken. They are highly accurate!

Results of the search query “a roasted chicken”.
This is the minimum implementation of the core of the image search engine. Sounds easy, right? CLIP's excellent ability to recognize key concepts among text and images makes it a powerful backbone for image search applications.
However, there is a big problem: for each search, we need to compute the similarity between the search query and 10,000 images. This takes 91.74 seconds on a P100 GPU, which is too slow for a real-world application. We need to optimize the latency to improve performance.
12,500x Speed Up
We have implemented two simple techniques that significantly reduce search latency from close to 100 seconds down to 8 milliseconds (12,500x speed up!) for 10,000 images.
Pre-Compute Image Embeddings
Since we have all the images ready at the start, we can pre-compute their embeddings and reuse them. This means that at the time of search, we only need to compute the embedding of the search query on the fly.
During web server startup, we can load all the pre-computed embeddings into cache, allowing for faster retrieval of image features. With this technique, we reduce the search time down to 12.38 seconds (7.4x speed up).
Fast Similarity Search on Dense Vectors
The next biggest bottleneck in latency is computing the similarity scores. We can speed this up using FAISS (Facebook AI Similarity Search). FAISS is an open-source software library that provides efficient and scalable solutions for similarity search and clustering of high-dimensional vectors. It is a perfect fit for our use case.
We used faiss.IndexFlatIP (Exact Search for Inner Product) to query 10,000 image embedding vectors of dimension 512. When a search query is received, FAISS searches the pre-loaded image embeddings with the query's text embedding and extracts the top 10 similar images. The code block below provides an example of using faiss.IndexFlatIP.

From our benchmark, we find FAISS to be very robust to the growth of the dataset size. We show the latency of searching through N images in the plot below. The latency is 7.3 ms on 1,000 images and 9.5 ms on 10,000 images. It is blazingly fast!
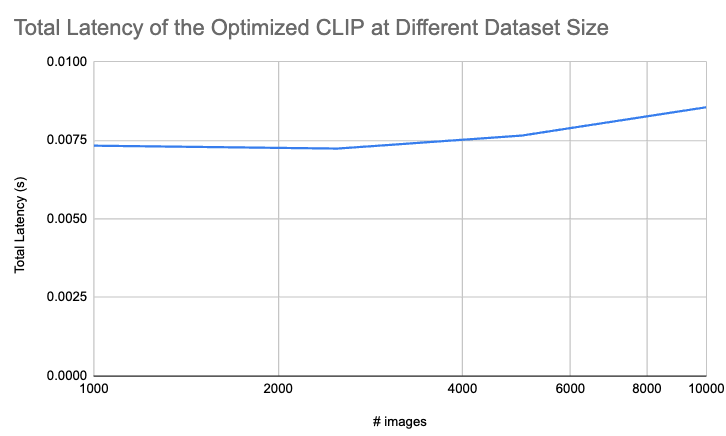
The latency of searching through N images with the optimized CLIP.
Some More Examples
Below are additional examples of search results. Through these examples, CLIP demonstrates its ability to capture fine-grained details, multiple objects (such as sunsets and oceans, and vintage cars), and abstract terms (such as romantic couples). It can search not only for key objects, but also for more descriptive phrases (such as locations, conditions, and states). This makes CLIP a powerful tool for image search applications.

Results for the search query “Beautiful sunset over the ocean”

Results for the search query “vintage cars on a street”

Results for the search query “dogs playing in the park”

Results for the search query “Romantic Couple”
Adding GLIP
Our experiment shows that the CLI model does not always retrieve accurate images. For instance, when searching for romantic human couples, the first and third images returned by the system are correct, but the middle one is not. Although the image depicts love locks, a concept related to romantic human couples, there are no humans in the picture. While highly relevant conceptually, it is not what the users are looking for.

This highlights a weakness of the CLIP-based system: it surfaces images that it believes to be highly relevant to the text query conceptually, but sometimes the results may lack the concrete objects that are explicitly requested in the query. To address this issue, we introduce GLIP as a critique to filter out incorrect images.
GLIP is a foundation model that is pre-trained using language-image paired data. During pre-training, it generates bounding boxes on image-text pairs in a self-training process and learns semantic-rich visual representations. As a result, it is not only able to identify which visual concepts are present in an image but also where they are located. GLIP has demonstrated strong zero-shot performance in various object-level recognition tasks.
In our application, we have found GLIP to be very helpful in validating whether the target objects are present in similar images returned from CLIP. GLIP takes (image, text) as input and returns all detected objects that are part of the text query, along with the exact locations and confidence scores.
We adopted the implementation of GLIP found here. It is worth noting that this implementation has a strict requirement on CUDA and PyTorch. Its build failed for all PyTorch versions above 1.9. Therefore, we ran it using CUDA 1.10 and torch==1.0.1+cu111.
The code block below shows an example usage of GLIP. The full implementation can be found in our GitHub repository here. Note that I skip the conversion from labels to the class names in the code block below. GLIP has its own way of tokenizing query into phrases. For simplicity, we skip that part in the code below.

You can see how CLIP and CLIP are utilized together to generate the final output here.
Here are the results for the search query romantic human couples, as generated by the CLIP+GLIP system. As you can see, among all candidate images surfaced up by CLIP, GLIP validates if each image contains actual human and add a bounding box on the detected objects. This helps improve the precision to the search results and also add explainability to the system.

Results from CLIP+GLIP system for the search query “romantic human couples”.
Benchmark Results
An ideal image search system must quickly find relevant images for a given search query. Therefore, we evaluate the system's performance and latency.
Performance
In our evaluation process, we aim to assess the quality of the images returned in response to a search query. In particular, we report on three key metrics that allow us to evaluate the relevance of the images returned.
Precision: This metric measures the precision of all the images that are returned with respect to the search query, regardless of their rank. By doing so, we are able to get a sense of the overall relevancy of all images that are returned.
Mean Reciprocal Rank (MRR): The goal of this metric is to ensure that the results that are most relevant to the search query are placed at the top of the list of images that are returned. The MRR metric measures how close the first relevant item is to the top.
Average Precision: While MRR is a useful metric for ensuring that the most relevant results are at the top, it doesn't evaluate the rest of the list of returned items. By contrast, Average Precision takes into account the ranking and relevancy of all images that are returned. This allows us to get a more comprehensive understanding of the quality of the images that are returned in response to a search query.
We evaluated the performance of both systems using 20 image search queries. First, we generated candidate queries with ChatGPT, and then hand-picked the ones that were meaningful. Note some queries are challenging and may not be covered by the dataset we have. We report the performance metrics of the CLIP and CLIP+GLIP systems in the table below.
| Metric | CLIP | CLIP + GLIP |
|---|---|---|
| Precision | 0.567 | 0.685 |
| Mean Reciprocal Rank | 0.775 | 0.778 |
| Average Precision | 0.639 | 0.719 |
From the table above, we can see that the CLIP-only system achieves a precision of 0.567 and a MRR of 0.775. This indicates that the system is capable of delivering highly relevant images at the top of the returned results, but there are several false positives at the lower ranks. This aligns with our observations when testing the app: the first result is often relevant to the query, but the relevancy deteriorates in the lower ranked results.
Adding GLIP to the CLIP model improved the system's performance in all three metrics. The precision increased from 0.567 to 0.685, and the average precision improved from 0.639 to 0.719. These two metrics show that GLIP, as the critic filter, improves the overall relevancy of all results. On the other hand, the mean reciprocal rank remained relatively stable, indicating that the improvement to the relevancy of the top results is limited.
In conclusion, the CLIP-based image search system is able to generate highly relevant images at the top of the returned results. Adding GLIP helps improve the relevancy of the overall results by filtering out irrelevant images after the top rank.
Latency
We conducted a benchmark study to measure the latency of image search using different implementations, hardware, and image sample sizes. The results are presented below. To ensure stable measurements, we prepared 10 search queries and ran each query three times. We then calculated the average latency required to search through the entire image set per query.
| Model | Search Time (sec) | Image Sample Size | Device |
|---|---|---|---|
| CLIP (OpenAI) | 15.751 | 1000 | MacBook Pro M1 Max |
| CLIP (Optimized) | 0.035 | 1000 | MacBook Pro M1 Max |
| CLIP (OpenAI) | 4.287 | 1000 | A4000 GPU |
| CLIP (Optimized) | 0.005 | 1000 | A4000 GPU |
| CLIP (Optimized) | 0.0076 | 10000 | A4000 GPU |
| CLIP (OpenAI) | 8.660 | 1000 | Nvidia P100 |
| CLIP (Optimized) | 0.0073 | 1000 | Nvidia P100 |
| CLIP (Optimized) | 0.0085 | 10000 | Nvidia P100 |
| GLIP | 0.418 | 1 | Nvidia P100 |
Summary
I hope you find this blog helpful in understanding how we designed this image search system and how we evaluated and optimized each of its components. Leveraging the capabilities of foundation models, CLIP and GLIP, we created a fast and simple image search system that can handle complex queries and find relevant images instantly.
We built a simple local web app to showcase its capability. We may make it available online later. For now, you can find all the source code in our GitHub repository: https://github.com/Ivan-Zhou/image-search/.
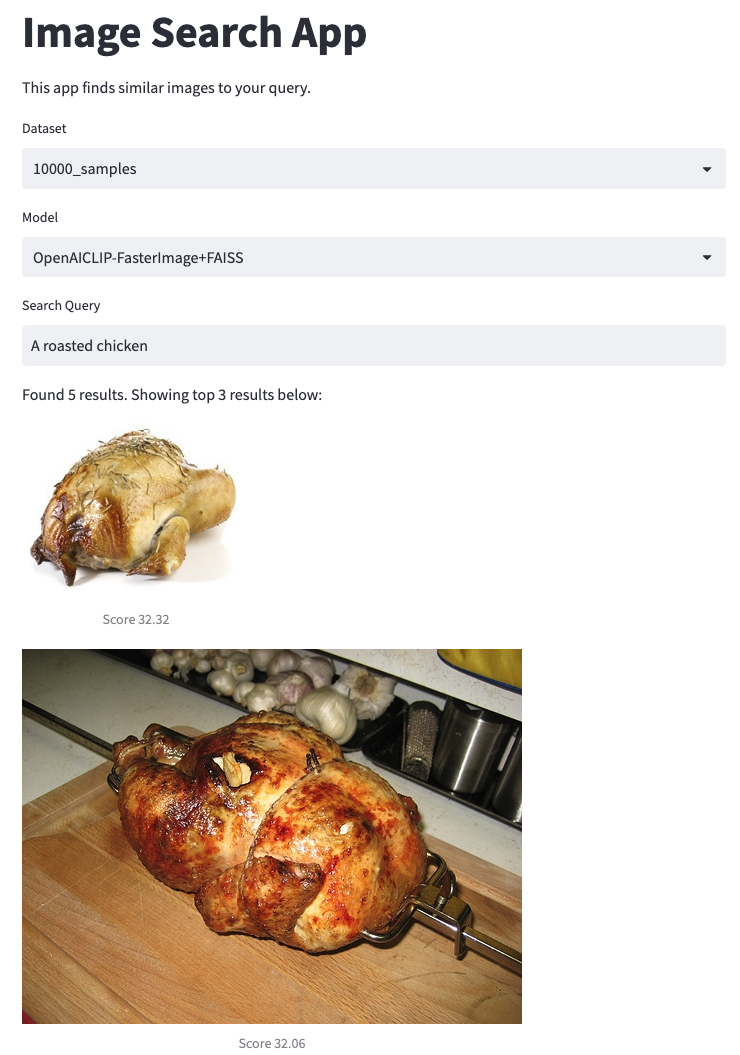
A screenshot of our image search app.
We also created a video walk through of our image search app. You can watch it below: