
As we enter the week of NeurIPS and approach the end of the year, I expect we will see many releases this week. On Monday, DeepSeek launched its V3.2 model, together with an experimental V3.2 Speciale (tweet). Both models are built “reasoning-first” and for agentic workflows. I read the technical report (here) and really enjoy the amount of technical details and empirical findings shared openly by the team.
At a very high level, DeepSeek V3.2 is a top-tier LLM. DeepSeek V3.2 generally outperforms other open-source models across benchmarks for reasoning, coding, and tool-use, though it consistently falls behind the latest proprietary Gemini 3.0 Pro. V3.2 Speciale, on the other hand, achieves performance that is on-par with or even exceeds Gemini 3.0 Pro, albeit at the cost of 40-100% more reasoning tokens. V3.2 is insanely cheap: its output token price is 28.5x cheaper than Gemini 3.0 Pro and even 5x cheaper than GPT-5.1 mini.
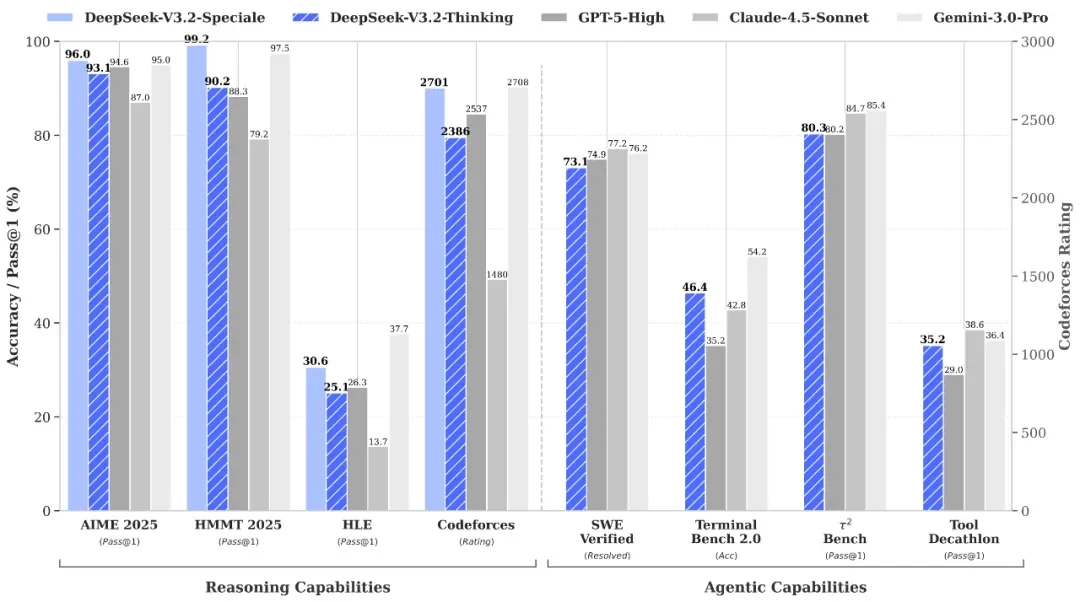
Evaluation of DeepSeek V3.2 on reasoning and agentic workflows
The technical report provides much more information beyond the evaluation and is worth a closer read. I am going to cover a few interesting sections from my reading.
Thinking in Tool-Use
I find the section 3.2 the most interesting to me. The team first explains a new context management protocol for tool-use. They observed that discarding reasoning tokens at a new round of messages, which is a common practice, forces the model to re-reason at subsequent tool call, resulting in significant token inefficiency. Therefore, the team proposes a new context management method tailored for tool-calling:
Historical reasoning content is discarded only when a new user message is introduced to the conversation.
Reasoning content is retained if only tool outputs are appended.
The history of tool calls and tool outputs are preserved in the context.
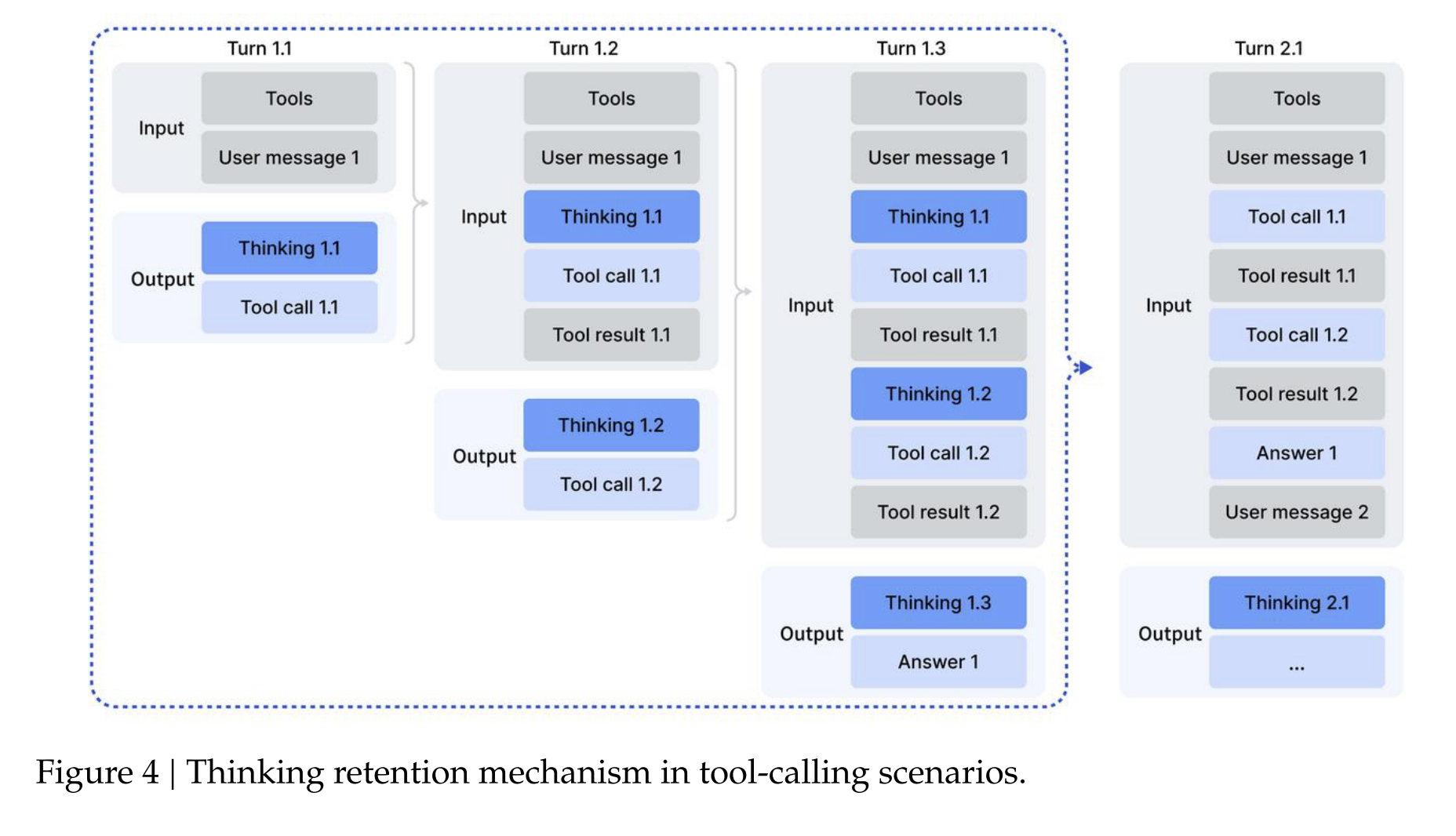
New context management protocol for reasoning at multiple tool-calls
They constructed ~85k agentic tasks across domains with environment, tools, task, and verifier. The paper provides very rich details about how they build these instances. For example, to collect examples for the search agent:
Sample long-tail entities from large-scale web corpora
Construct questions: an agent explores each entity using search tools with configurable parameters and build Q&A pairs
Answer generation: generate diverse candidate responses using multiple agents with different checkpoints and system prompts
Verify correctness: an agent validates candidate response using the web search tool and retain those that are verified correct or incorrect.
Develop detailed evaluation rubrics across multiple quality dimensions and employ a generative reward model to score responses based on the rubrics.
Lastly but importantly, run through a checkpoint and retain only instances with non-zero pass@100.
Reading through their data generation pipelines for each of the agent tasks, the common considerations are:
Important criteria: tasks are hard to solve but easy/feasible to verify. The verification can be done via a list of tool-calls in a notebook (verify the total costs of a trip does not exceed a given budget, for example).
Fully leverage multi-step and multiple agents with tools to synthesize questions, generate candidate answers, and validate them.
Reflective process: if a solution cannot be validated, an agent can modify the solution or verification functions until the solution’s output passes the verification. If the current toolset is not sufficient to solve the task, an agent can augment the toolset.
Iterative process: agent can iteratively increases the difficulty of the task and updates the corresponding solution and verification functions.
Cheap Price
I found the pricing of DeepSeek V3.2 insanely cheap (from their API pricing page here), compared to other frontier models and even the low-cost variant (GPT-5-mini).
| DeepSeek V3.2 | Gemini 3.0 Pro | GPT 5.1 | GPT 5 mini | |
|---|---|---|---|---|
| Input Tokens ($/M) | 0.28 | 2.00 | 1.25 | 0.25 |
| Cached Input Tokens ($/M) | 0.028 | 0.2 | 0.125 | 0.025 |
| Output Tokens ($/M) | 0.42 | 12 | 10 | 2.00 |
This is even cheaper than DeepSeek R1 and V3.1, as shown in the plot below.
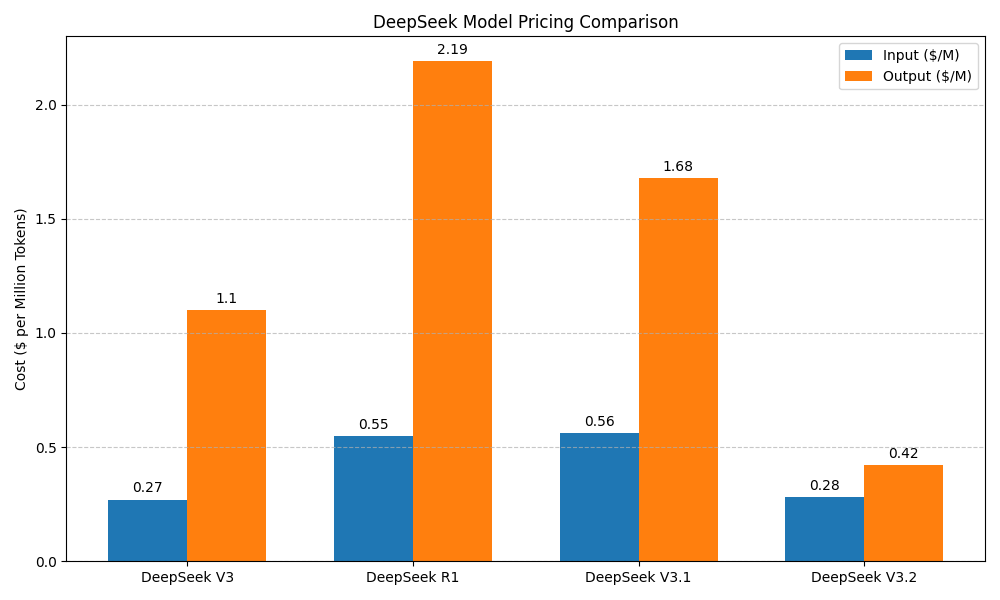
Comparison of price across different DeepSeek version.
This gain on efficiency primarily comes from the new DeepSeek Sparse Attention (DSA) architecture, which introduces a fine-grain token selection mechanism that retrieves only top-k key-value entries based on an efficient indexer.
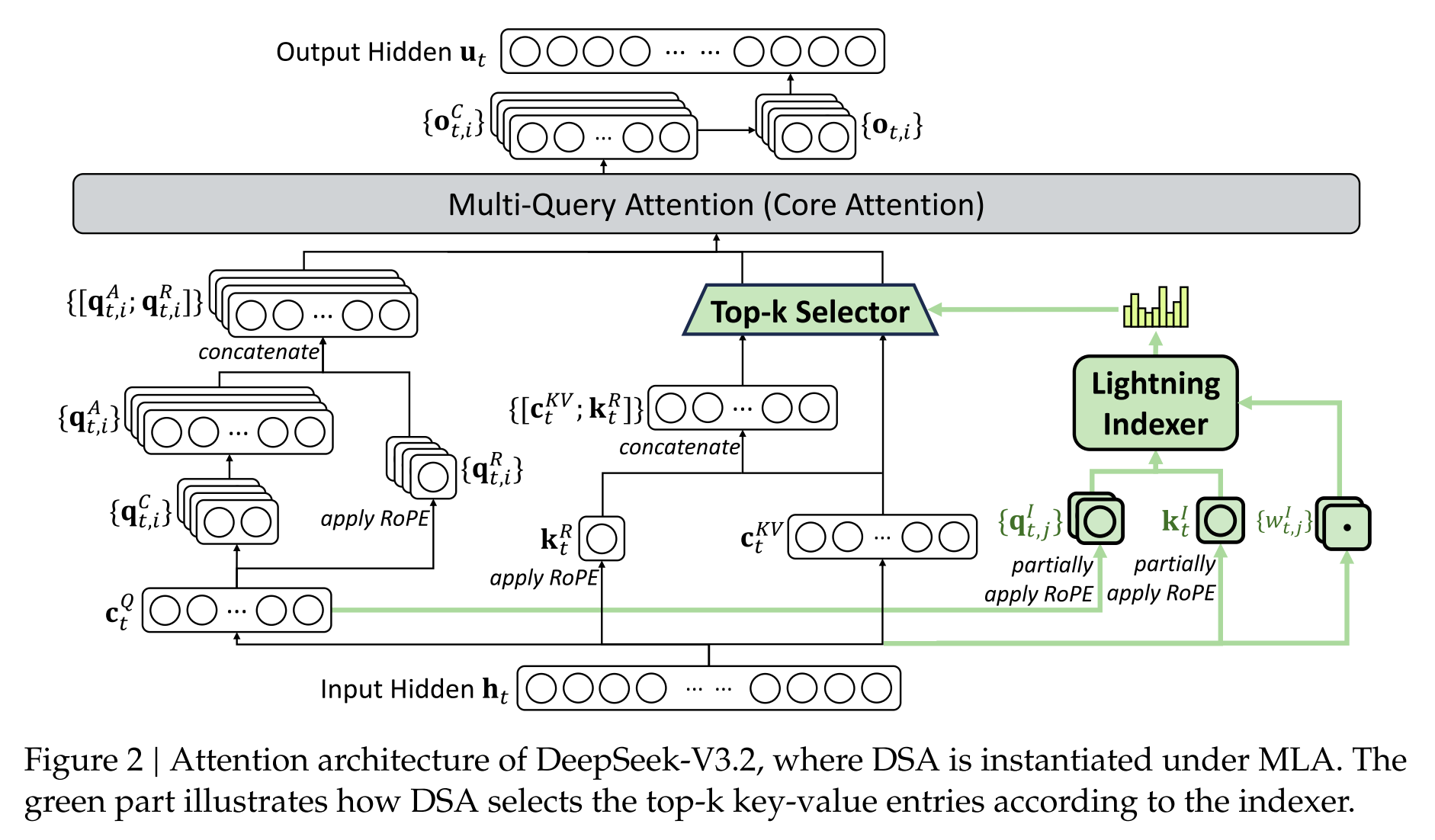
New DeepSeek Sparse Attention architecture
However, note that the DeepSeek V3.2 has a context length of only 128K, which is drastically smaller than Gemini 3.0 Pro (1M) and GPT 5.1 (400k). As a result, DeepSeek V3.2 faces significant challenge at agentic workflows. For example, on the search agent benchmarks, 20% test cases exceed the context limit. Therefore, it requires context management when being used for long conversations and agentic workflow.
Post-Training Methods
DeepSeek V3.2 is trained from V3.1’s base checkpoint. It went through a continued pre-training to adapt to the new DSA architecture, but the performance gains primarily come from post-training.
First, the base model goes through Specialist Distillation (domain-specific SFT):
The team fine-tuned multiple specialist models for different domains, then generate domain-specific training data for long Chain-of-Thought reasoning as well as direct responses.
The specialists cover domains including writing and general question-answering, maths, programming, logical reasoning, agentic coding, agentic search, and general agentic tasks.
The fine-tuned models achieves performance levels that only marginally below the specialists, then the team closes the performance gap through the RL stage.
The team still uses the GRPO algorithm (Group Relative Policy Optimization); however, they looked into various optimization strategies to stabilize RL training at scale, including:
Obtain an unbiased KL estimate using the importance-sampling ratio between current and old policy to eliminate estimation errors.
Mask negative sequences that introduces significant divergence between policies (measured by KL divergence) to address off-policy from a large batch of rollouts that are split into several steps.
Preserve the expert routing paths used during sampling in the inference framework and enforce them during training, so that same expert parameters are optimized.
Ensure both the old and the current policy share the identical action subspaces by preserving the truncation masks during sampling.
The DeepSeek team merge all reasoning, agentic tasks, and human alignment training into one RL stage. The “one RL for all” approach helps balance performance across domains while preventing the catastrophic forgetting issues.
In terms of the reward designs during RL:
For reasoning and agentic tasks: rule-based output reward, length penalty, and language consistency reward.
For general task: a generative reward model is paired with evaluation rubrics that are specific to prompts.
Reflection on Scaling Post-Training
In the section 4.1, the DeepSeek team made an observation of consistent performance improvement from additional computational budget:
Over recent months, we have observed consistent performance improvements correlating with extended RL training budget, which already exceeds 10% of the pre-training cost. We hypothesize that reasoning capabilities could be further enhanced with additional computational budget allocation.
This signals that additional performance gains can potentially be unlocked by more investment on model training. I am fairly optimistic that we will see even better open-source models coming next year, if not later this December :)